
Chat bots are taking the internet by storm. A huge amount of attention and jobs are directed towards them for their wide range of uses.
In this post we’ll build a very basic Fatwa chat bot, but first what’s Fatwa?
In Islam the act of asking for a ruling on a case is called a Fatwa, in other words it’s a question you ask a recognized authority to receive an answer which is a ruling on your point.
Now what has this got to do with a Chat bot? Issuing a Fatwa is in some sense answering a question which is a task a Chat bot is capable of doing. We will try to abstract the process of issuing a Fatwa into a basic question answering task although we are aware that abstracting a complex inference task like this into a simple problem will produce unreliable results however we will do that for the sake of playing with a chat bot.
Our Toolbox
We’re going to use Python 3 along some libraries which include:
Types of Chat Bots
- Retrieval Based
- Generative
Each approach has its use case, based on your application and your abilities you decide which one to use.
The retrieval based bots work by having a pre defined data set of Questions/Answers and a similarity measure to decide which question in the data set is most similar to the one asked.
The generative models work by training a neural network to output an answer given a certain input question without needing a data set to lookup.
Data set
In order to build a chat bot we will first need data to teach it to talk, I’m going to use the Arabic AskFM dataset which is a data set of Question/Answer pairs in Fatwa gathered from Ask.fm (Further discussed in this post)
Let’s explore the data using Pandas and see what’s inside.
import pandas as pd
data = pd.read_csv("askfm/full_dataset.csv")
In [7]: data.columns Out[7]: Index([u'Question', u'Answer'], dtype='object')
In [8]: data.describe()
Out[8]:
Question Answer
count 98422 98422
unique 95572 84979
top تسلية الصابرين اليوم؟! لا
freq 71 2286
That is almost 100k question answer pairs.
Code
You can find all the code for this tutorial on my Github.
Let’s try to build a retrieval based chat bot and see how will it perform, but first we need to understand how do they work.
Retrieval based bots
These bots rely on the similarity between the input question and all the questions in the data set. In order to compute this similarity we need to choose a similarity measure that would rate the similarity of two sentences, there are a lot of similarity measures for text but we will choose the cosine similarity for this one since it’s one of the most common measures in NLP.
Cosine similarity
How does the cosine similarity work?
It works by measuring the cosine of the angle between two vectors, thus it is concerned by their directions rather than their magnitudes, which in text represents the term frequency in each question regardless of the document length, in other words the length of the documents(questions) will not affect the computation but only. You can see that in the equation:
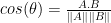
Where the dot product is normalized by the norm (Magnitude) of the two document vectors.
But wait a second, we’ve been discussing vectors vectors vectors, what are these vectors and how do we obtain them, I thought we had text questions?!
Vectorizing questions
To go from a text question to a vector that represents the question so we can compute the similarity we need to transform it, in order to transform a text document into a vector we need to use a feature extraction technique, we will use TF-IDF because it’s the most common in NLP.
How does TF-IDF work?
TF-IDF is computed by first computing two values for each term:
- Term Frequency: The frequency of the term in the document
- Document Frequency: The fraction of the documents that contain the term
- Inverse Document Frequency: The logarithmically scaled inverse Document Frequency
The term frequency is used because we are concerned with finding documents that have similar terms, because if two documents have the same terms then they are probably very similar.
The inverse document frequency is used to measure how much information does each term carry, since terms like “The” will appear in almost every document then it will have a high document frequency, thus a term with low document frequency is favored over a term with high document frequency for the sake of specificity (Thus the inverse relation).
Think of this example, will the term “Acetaldhyde” carry information that will help identify the document as chemistry related or the term “The” which exists in every document?
Enough with the explanation and let’s see how can we use TFIDF and Cosine Similarity to build a retrieval based chat bot.
Recall we already hold our data set in the variable “data”.
from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.metrics.pairwise import cosine_similarity import numpy as np vectorizer = TfidfVectorizer() vectorizer.fit(data.values.ravel())
Now our vectorizer is ready to transform any question into a vector using TFIDF!
Let’s see what can it do.
# Read a question from the user
question = [input('Please enter a question: \n')]
question = vectorizer.transform(question)
# Rank all the questions using cosine similarity to the input question
rank = cosine_similarity(question, vectorizer
.transform(data['Question'].values))
# Grab the top 5
top = np.argsort(rank, axis=-1).T[-5:].tolist()
# Print top 5
for item in top:
print(data['Answer'].iloc[item].values[0])
print("\n ########## \n")
Giving it a question to see if it can produce reasonable output:
Please enter a question: هل السرقة حرام؟ قال الشيخ مرعي الكرمي في دليل الطالب: " ويجب - أي القطع في السرقة - بثمانية شروط: أحدها: السرقة وهي: أخذ مال الغير من مالكه أو نائبه على وجه الاختفاء، فلا قطع على: منتهب ومختطف وخائن في وديعة. الثاني : كونه السارق مكلفًا مختارًا عالمًا بأن ما سرقه يساوي نصابًا. الثالث : كون المسروق مالاً، لكن لا قطع بسرقة الماء ولا بإناء فيه خمر أو ماء، ولا بسرقة مصحف، ولا بما عليه من حلي ولا بكتب بدع وتصاوير ولا بآلة لهو ولا بصليب أو صنم. الرابع : كون المسروق نصابًا، وهو: ثلاثة دراهم أو ربع دينار أو ما يساوي أحدهما وتعتبر القيمة حال الإخراج. الخامس : إخراجه من حرز فلو سرق من غير حرز فلا قطع، وحرز كل مال: ما حفظ فيه عادة .. السادس : انتفاء الشبهة: فلا قطع بسرقته من مال فروعه (أي أبنائه وأحفاده) وأصوله (أي آبائه وأجداده) وزوجه ولا بسرقة من مال له فيه شرك أو لأحد ممن ذكر. السابع : ثبوتها، إما بشهادة عدلين ويصفانها ولا تسمع قبل الدعوى، أو بإقرار مرتين ولا يرجع حتى يقطع. الثامن : مطالبة المسروق منه بماله. ولا قطع عام مجاعة غلاء" ا.هـ. ملخصًا والقطع إنما يكون للإمام (السلطان) أو نائبه ########## الحدود معطلة في نظام القوانين الوضعية الذي يحكمنا، الفكرة بس إن الحكومة التونسية عبر تاريخها من بعد الاستعمار= أوغل في الكفر والعلمنة، وأدخلت التعطيل لمناطق حتى الدول العلمانية العربية حريصة على عدم الدخول فيها (حتى الآن). ########## الحمد لله وحده. حرام وكبيرة من الكبائر. والدليل: قول الله تعالى: (والسارق والسارقة فاقطعوا أيديهما جزاء بما كسبا نكالا من الله). وفي الصحيحين أن رسول الله صلى الله عليه وسلم قال: (لعن الله السارق ...) الحديث. ولا فرق بين مال عام ومال خاص، وقد ذكر الشافعي نصا أن سرقة مال يشترك في ملكه المسلمون؛ أولى بالتحريم. ومال بنزينة الجيش مال عام للمسلمين، وكذلك مال الكهرباء، وتذاكر القطارات والمترو والمواصلات العامة. فمن سرق منها شيئا فهو السارق، سواء كان موظفا أو شخصا منتفعا بالخدمة أو أيا كان. ومن قال إن المجرمين والمرتشين والفسدة يسرقونها، فنعم هذا صحيح. ولذلك فهم مجرمون فاسفون فاسدون، فالصالحون لا يشاركونهم في جريمتهم قط.. وكون المجرمين يسرقونها، لا يجعل المال مستباحا، بل هو باق على ما هو عليه، وكل من أخذ منه فهو سارق مجرم مثلهم. ومن تلبس بشيء من هذه السرقات فسبيل التوبة أن يندم ويعزم على عدم العودة، وأن يرد هذه الأموال لأصحابها. وأصحابها هم عموم الناس، فيمكن أن يتصدق على الفقراء، أو يتبرع بها للمستشفيات الحكومية، أو يشتري بها أدوية للمستشفيات الحكومية، أو نحو ذلك من المصالح العامة الداخلة في واجبات هذه الدولة الضالة المنهوبة. ولا يجوز عندي إتلاف المال، فلا يشتري تذكرة قطار ويقطعها بدل ركوبه السابق خلسة، ولا نحو ذلك. فهذا أيضا إتلاف للمال، لا أعلم شيئا يبيحه. وسواء في ذلك بنزينة الجيش أو أي مصلحة حكومية. والله أعلم. ########## حرام ########## نعم ##########
This is a very simple question and therefore the results are good given the very simple approach we’re following.
You can find the whole code for this script under the name of tfidf-chatbot.py
Another approach to vectorizing input questions is by encoding them using an LSTM model. This is more advanced than TFIDF and requires more data (Which I don’t think is enough here).
LSTM Encoding
Before we look into LSTM or Encoding let’s first understand what is an Auto encoder.
An Auto encoder is a Neural Network whose sole job is to output the same input it received, sounds easy right? The trick is that the way it is designed forces the Neural Network to lose some of the information it received therefore by training the network you’re basically training it to find the optimal compression method or the optimal representation for the input it receives.

We can say that this network is encoding the input into a lower dimension which is the hidden layer and it has all the useful information that the network needs to reconstruct the input.
We can extend the Auto encoder to work with text which has an extra dimension that is the time (Since order of terms matters significantly in language).
For this we can build an LSTM auto encoder. LSTM is short for Long Short Term Memory, which is an algorithm that is capable of dealing with sequences of input. For an excellent tutorial on LSTM I highly advise reading this blog post by Christopher Olah.
We will use Keras to build an LSTM auto encoder, because the code is a lot more complex than the previous chat bot I’m going to explain the important bits here and I will upload the full script to Github.
First Let’s load the required libraries
from keras.preprocessing.text import Tokenizer from keras.preprocessing.sequence import pad_sequences from keras.models import Sequential from keras.layers import Dense, Embedding, LSTM, RepeatVector from keras.utils import np_utils
Because a neural network works with fixed length input, we need to define this length by getting rid or trimming inputs that are longer than this length and padding inputs that are shorter than this length.
Let’s define our length limit to be 20 words.
MAX_LEN = 20 train_data = train_data[train_data.Question.apply(lambda x: len(x.split())) < MAX_LEN]
Now that we dropped long questions let’s clean text.
We can use a regular expression to remove anything that is not an Arabic character.
train_data.Question = train_data.Question.apply(lambda x: (re.sub('[^\u0620-\uFEF0\s]', '', x)).strip())
We can optionally use a stemmer, which in my opinion will improve the process since we haven’t got much data.
stemmer = ISRIStemmer() train_data.Question = train_data.Question.apply(lambda x: " ".join([stemmer.stem(i) for i in x.split()]))
Now it’s time for Tokenization. Tokenization is the process of reading the text we have and creating a vocabulary based on some parameters, then using this vocabulary we define an index where every word in the vocabulary has its ID.
tokenizer = Tokenizer(num_words=NUM_WORDS, lower=False) tokenizer.fit_on_texts(train_data["Question"].values) train_data = tokenizer.texts_to_sequences(train_data["Question"].values)
We have to pad sequences that are shorter than MAX_LEN
train_data = pad_sequences(train_data, padding='post', truncating='post', maxlen=MAX_LEN)
Now our data is ready to train the model, let’s define our model and train it.
model = Sequential() model.add(Embedding(NUM_WORDS, 100, input_length=MAX_LEN)) model.add(LSTM(LSTM_EMBED, dropout=0.2, recurrent_dropout=0.2, input_shape=(train_data.shape[1], NUM_WORDS))) model.add(RepeatVector(train_data.shape[-1])) model.add(LSTM(LSTM_EMBED, dropout=0.2, recurrent_dropout=0.2, return_sequences=True)) model.add(Dense(NUM_WORDS, activation='softmax')) model.compile(loss='sparse_categorical_crossentropy', optimizer='adam') model.fit(train_data, np.expand_dims(train_data, -1), epochs=5, batch_size=BATCH_SIZE)
The embedding layer creates a word vector for each token in our vocabulary, it’s useful because it learns what words are closer to each other and tries to embed this information in the word vectors.
The LSTM layers will encode and decode the sequence.
The Repeat vector layer is used as a hack to keep the hidden layer vector constant across the time steps, because we want to have one hidden layer vector which is the result of encoding the input sequence and from this vector we will decode the sequence back.
We can finally save the model for later use.
model.save("models/lstm-encoder.h5")
After our model is saved we can later use it to encode our question and follow the same retrieval process.
The script for training the LSTM auto encoder is available under the name of lstm-train-autoencoder.py, the script that uses the output model for retrieval is named lstm-retrieval-chatbot.py which is essentially the same script as the TFIDF chat bot but with the LSTM model as the vectorizer.
Enough with the retrieval bots, what about the more advanced Generative chat bots? Let’s take a look at how they work and what has deep learning got to offer us.
Generative based chat bots
A generative chat bot is a bot that doesn’t use a data set of questions for lookup but rather than that uses a neural network to output the answer all by itself.
You could use a generative model rather than a retrieval model because retrieval based models are awful at sounding human and are easily spotted and easily deceived while generative models are a lot better at this point.
However generative models do a lot of logical and grammatical mistakes which makes them immature for a lot of applications.
Let’s now discuss how do these models work and see an example on building one.
The cornerstone of a generative chat bot is the Seq2Seq model which is the go to standard in Machine translation. This model is in fact two models working on top of each other, the first being an encoder model that is concerned with encoding the input sequence into a vector (or more) that represent the input sequence. The other model being a decoder that is capable of creating the output given this encoded vector, whether that is a translation of the input sequence to another language or an answer to a question that was input.
You can read more about Seq2Seq in its Tensorflow Tutorial.
However there’s a layer that stands before the Seq2Seq model which is the Word2Vec model which is responsible for producing word vectors for each word based on a corpus it was trained on. Word2Vec models are trained on gigantic corpora like the full Wikipedia dump. You can read more about Word2Vec in these posts: Word2Vec for product recommendations The amazing power of word vectors
Back to building a generative chat bot with the Seq2Seq model.
We’re going to use the Seq2Seq Python package which is built using Keras, you can find it at this github repo
First let’s load our Keras and Seq2Seq tools.
from keras.preprocessing.text import Tokenizer from keras.preprocessing.sequence import pad_sequences from keras.models import Sequential from keras.layers import Embedding from keras.utils import np_utils import seq2seq from seq2seq.models import AttentionSeq2Seq
We’ll follow the same preprocessing steps for the LSTM Autoencoder but this time we’ll also preprocess the Answers because these are our target variable (The output of our chat bot).
data = data[data.Answer.apply(lambda x: len(x.split())) < MAX_LEN]
data = data[data.Question.apply(lambda x: len(x.split())) < MAX_LEN]
data.Question = data.Question.apply(lambda x: (re.sub('[^\u0620-\uFEF0\s]', '', x)).strip())
data.Answer = data.Answer.apply(lambda x: (re.sub('[^\u0620-\uFEF0\s]', '', x)).strip())
data = data[data.Answer.apply(len) > 0]
data = data[data.Question.apply(len) > 0]
data.Question = data.Question.apply(lambda x: " ".join([stemmer.stem(i) for i in x.split()]))
data.Answer = data.Answer.apply(lambda x: " ".join([stemmer.stem(i) for i in x.split()]))
tokenizer = Tokenizer(num_words=NUM_WORDS, lower=False)
train_data = pd.concat((data.Question, data.Answer), ignore_index=True)
tokenizer.fit_on_texts(train_data)
Now we turn our inputs (Questions) and our outputs (Answers) into sequences of tokens and pad them for the LSTM (Remember we need a fixed size input)
Questions = tokenizer.texts_to_sequences(data.Question) Answers = tokenizer.texts_to_sequences(data.Answer) Questions = pad_sequences(Questions, padding='post', truncating='post', maxlen=MAX_LEN) Answers = pad_sequences(Answers, padding='post', truncating='post', maxlen=MAX_LEN)
Finally we define the model and train it then save it.
model = Sequential()
model.add(Embedding(NUM_WORDS, 200, input_length=MAX_LEN))
attn = AttentionSeq2Seq(batch_input_shape=(None, 15, 200), hidden_dim=10, output_length=MAX_LEN, output_dim=NUM_WORDS, depth=1)
model.add(attn)
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam')
model.fit(Questions, np.expand_dims(Answers, 2), batch_size=BATCH_SIZE, epochs=25)
model.save("models/lstm-seq2seq.h5")
You can find the code in the script lstm-train-seq2seq.py
After you’ve trained the model you can test it, I’ve created a script to test it at lstm-generative-chatbot.py
The problem with this model is going to be the lack of data as a huge model like this one would require a very big data set which is not the case here, but at least we’ve tried!
Be First to Comment